
Database Programming :: Lessons :: Relational Databases
Relational Database Structure
A relation, or table, is a named collections of rows and columns of related data. It can be written as Relation_Name (A1, A2, ..., An) where each column is a named attribute. The domain of an attribute is the constraints put upon that attribute. For example, a batting average attribute would be constrained between 0 and 1 since a batting average cannot exceed 1. An attribute must also be made up of atomic values, meaning each attribute cannot store more than one item. For example, you could not store all of the classes a student takes in one attribute. In these cases you probably need another table to store the needed data. The rows of a table are also known as tuples and are similar to a record. Each row represents a unique entry in the table.
| A1 | A2 | ... | ... | ... | An |
|---|---|---|---|---|---|
A super key is an attribute or set of attributes that uniquely identifies a tuple. A relation can have more than one super key, and every relationship has at least one super key, which is the set of all attributes.
A candidate key is a minimal super key, or a minimum set of attributes that uniquely identifies a tuple. A relation may have more than one candidate key. The primary key of a relation is the chosen candidate key of that relation. A relation can have only one primary key. You can see some key examples for the Student and Assignment examples below. Once the primary key is found, you can underline it in the written form of the relation to indicate it.
Student (Student_ID, Student_Name, Birthday, Address, Grade)
- Super Key:
- Student_ID, Address
- Student_Name, Birthday, Grade
- Candidate Key:
- Student_ID
- Student_Name, Birthday
- Primary Key:
- Student_ID
Assignment (Student_ID, Assignment_ID, Assignment_Title, Assignment_Points)
- Super Key:
- Student_ID, Assignment_ID, Assignment_Title
- Student_ID, Assignment_ID, Assignment_Points
- Candidate Key:
- Student_ID, Assignment_ID
- Primary Key:
- Student_ID, Assignment_ID
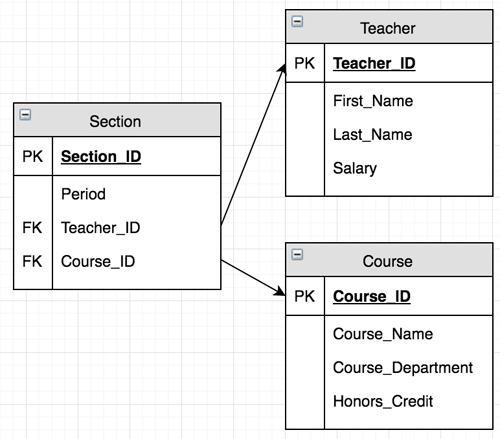
A foreign key is used to refer to another table. Attributes of a foreign key must have the same domain as the attribute in the home table. Below is a partial example of an attribute list where attributes and keys can be shown if they cannot fit on the ER diagram. Drawing the arrows in an attribute list is optional, but it can help to better show the connections between tables.
A null value signifies a missing attribute value. Try to use 0 or the empty string "" when possible. You should only allow null values in the following situations:
- The attribute is a future unknown date, such as the return date of a library book.
- An optional value where 0 would skew the stats, such as an ACT score for prospective college students. Not all students take the ACT and a value of 0 would skew the average.
- A foreign key value that may not match a primary key value. For example, the ID number of the patron who has checked out a library book. If the book hasn't been checked out, this field will be null.
Characteristics of a Relation
A table (relation) has order independence. This means a table is considered an unordered set and the tuples are not stored in any particular order. The attributes can also be stored in any order as long as the correspondence between the attribute and its values are maintained.
The domain integrity constraints specify the valid values of each attribute. For a "Grade" attribute in a "Student" table the valid values would be 9, 10, 11, and 12. The entity integrity constraint states that no attribute of a primary key can be null. Finally, the referential integrity constraint states that a foreign key must be null or contain a valid value of the primary key in the home table.


